

Neural Compiler#
The Neural Compiler automatically converts neural network models into Dataflow Programs (DFP) that dictate to MXAs how to configure their cores and manage dataflow operations, including the streaming of input data, performing inference, and streaming output data. The resulting DFPs can be directly loaded onto MXAs or executed using Simulator.
Compiler Flow#
The Neural Compiler is built as four layers with intermediate representations (IR) between the layers. This allows the compiler to scale efficiently across different chip sizes and generations. Similarly, the compiler can support multiple neural network frameworks in a way that is transparent to the deeper compiler layers. The four compiler layers are described in the following subsections.
Framework Interface#
The framework interface converts a source model built for a specific framework into an internal graph representation, allowing multiple framework interfaces to be supported transparently to the rest of the flow.
Graph Processing#
The graph processing layer optimizes the internal graph by fusing and splitting layers to run more efficiently on MXAs. It expands operator support by breaking down complex layers into simpler ones. These optimizations are lossless, with no weight or layer pruning. Graph processing also converts activation functions: some are exact while others are approximated.
Mapper#
The mapper works to optimally allocate resources available on the MXAs to run a neural network model. By default, it targets maximum throughput (FPS).
Assembler#
Finally, an assembler layer uses the mapping information to generate a single DFP file. This DFP is used to program the MXA(s) or run the hardware simulator.
Supported Frameworks#
The Neural Compiler currently supports 4 of the most widely used neural network frameworks:
Note
PyTorch models can be supported by exporting them to ONNX (for more information see tutorial on exporting to ONNX). Direct support for Pytorch 2 will be available in a future release.
Usage#
After installing the SDK, the Neural Compiler CLI can be run using mx_nc.
mx_nc -h
usage: mx_nc [-h] [--version] [-g] [-c] [-d] [-m [[...]]] ...
Refer to the Hello, MobileNet! for a quick start on running the Neural Compiler. The following tables provide a comprehensive list of the arguments that can be used to control the Neural Compiler.
See also
Required Argument#
Option |
Description |
|---|---|
-m, --model |
space separated list of model files to compile. The file extension indicates the model framework, according to the following table |
Framework |
Extensions |
|---|---|
Keras |
.h5, .json, .keras |
TensorFlow |
.pb, .meta |
TensorFlow-Lite |
.tflite |
ONNX |
.onnx |
System Selection#
Option |
Description |
|---|---|
-g, --chip_gen |
Target generation (default: mx3). |
-c, --num_chips |
Target number of chips (default: 4). Provide ‘0’ to automatically calculate the minimum required MXAs. For advanced usage, please see Test with Fewer Chips. |
Model Arguments#
Option |
Description |
|---|---|
-is, --input_shapes |
Input shape(s) for each model specified. This argument is necessary if the model input shapes cannot be inferred from the model itself. Please see Input Shape. |
--autocrop |
Automatically crop the pre/post-processing layers from the input model(s). NOTE: This feature is considered experimental, as it may sometimes crop layers that could have run on the MXA. |
--model_in_out |
JSON config file that contains the names of the input and output layers. Use this to extract a subgraph from the full graph. For example, to remove pre/post processing. |
--inputs |
The names of the input layers of the model(s). Can be used instead of |
--outputs |
The names of the output layers of the model(s). Can be used instead of |
Mapping Arguments#
Option |
Description |
|---|---|
-e, --effort |
|
-so, --show_optimization |
Animates mapper optimization steps in the terminal. |
-so_aux, --show_optimization_aux |
Animates mapper optimization steps in the terminal, including Aux Cores. |
--target_fps |
Sets the target FPS for the cores optimizer (default: float(‘inf’)) |
Advanced Precision Options#
Option |
Description |
|---|---|
-hpoc_file, -hpoc |
Optional JSON file used to increase precision for specified output channels. Can also be specified as a string of ints for simple cases by omitting the _file postfix. Please see here for more info. |
-bt, --weight_bits_table |
Optional JSON file with per-layer weight quantization information. Use this file to define precision values for selected layers. Valid precision values are 4, 8, and 16-bit. Please see here for more info. |
--exp_auto_dp |
Optional flag that will attempt to identify layers that could be sensitive to weight quantization and automatically set them to 16-bit. This option cannot be used in conjunction with |
-hpoc, --high_precision_output_channels |
Optional list of integers that specify the final layer output channels to increase precision. Model must have a single output or multiple outputs with the same number of channels. For more flexibility, refer to the |
-hpoc_file, --high_precision_output_channels_file |
Optional JSON file containing lists of integers that specify the final layer output channels to increase precision. For more details on how to create the JSON file, refer to this. |
Advanced General Options#
Option |
Description |
|---|---|
--input_format |
Specify the packing format used for host->chip transport (FP32, BF16, GBFloat80, RGB888). Default: BF16. NOTE: conversions happen internally. You must always use float32 or uint8 data with MXA runtime APIs. |
--extensions |
Space separated list of .nce files to extend / modify the compiler functionality. |
--allow_unsigned_extensions |
Allows execution of unsigned extensions for the Neural Compiler. An extension may execute arbitrary code, only run extensions from sources you trust! |
Other Arguments#
Option |
Description |
|---|---|
-h, --help |
Print the help information |
-v |
Controls how verbose the NC and its function calls will be. Repeat this option for more information (e.g. -vv). |
--dfp_fname |
Output dataflow program filename (defaults to ModelName.dfp). |
--sim_dfp |
Writes Simulator config to the DFP. Flag is not necessary if dfp is only used with real MXA Hardware. The resulting file can be used with simulator and real MXA hardware, but it will be larger in size. |
Be sure to check the troubleshooting page if you have issues running the Neural Compiler.
Multi-Model#
The Neural Compiler can automatically map multiple concurrent models to the target system. The user only needs to provide the Neural Compiler with the set of models to map:
mx_nc -v -m model_0.h5 model_1.h5
The Neural Compiler will optimally distribute the hardware resources among the models to achieve higher performance when mapping multiple models. Models are allowed to be from different frameworks (e.g. Keras, ONNX, Tensorflow).
mx_nc -v -m model_0.h5 model_1.onnx model_2.pb
Multiple Input Streams#
Typically, each of the compiled models will have its own input stream. This allows each model to work completely independent of each other.
Multi-Chip#
The Neural Compiler automatically distributes the workload of the given model(s) over the available chips. Essentially, a multi-chip system can be thought of as a larger single-chip system.
mx_nc -v -c 2 -m model_0.h5 model_1.h5
Input Shape#
When loading a neural network model, the Neural Compiler requires information about the model’s feature map shape for each layer. The Neural Compiler will attempt to infer these shapes for each input model. This information may not be present for some models, preventing the Neural Compiler from continuing execution. In these situations, the shapes of the input layers of those models must be passed into the Neural Compiler. This allows the rest of the layer shapes to be inferred, which is required for execution.
The following example demonstrates how to supply the input shape from the command line for the typical case of a single input model passed to the Neural Compiler.
mx_nc -m frozen_graph.pb -is "300,300,3"
For the multi-model scenario, provide one string per input model, according to the order of the models.
mx_nc -m classifier.h5 detector.pb -is "224,224,3" "300,300,3"
Some models may not require specifying input shapes in the multi-model case as they already have well-defined shapes for each layer. For those models, pass the string “auto” instead of a “shape” string, and the Neural Compiler will attempt to infer shapes for that model.
mx_nc -m classifier.h5 detector.pb -is "auto" "300,300,3"
Important
Input shapes must always be provided in channel-last order (i.e NHWC), even if ONNX models provided are channel-first order (NCHW). The Neural compiler will internally handle assigning the correct shape for each layer.
Note
The batch size should not be included when specifying input shape.
Model Cropping#
Some models might have some pre/post-processing steps as part of the model graph. However, many of these processing techniques do not use neural network operators. And hence, they would need to be run on the host instead of the MXA. The Neural Compiler provides an option for the users to crop the model graph in case of these non-neural-network pre/post operations. We provide two options to cut the model(s). The first option is to let the Neural Compiler predict the likely points of cropping and automatically crop the model for you. The second option provides full manual control over the cropping points.
The neural compiler provides a feature to automatically crop the model to remove likely pre/post-processing layers. This feature first predicts the points of cropping based on commonly occurring patterns of pre/post-processing in the popular AI models and then crops the model at those points.
Pass --autocrop flag to the neural compiler to use this feature. The automatically determined cropping points are displayed when the Neural Compiler is run with verbosity > 1 (-vv or higher)
mx_nc -m ssd_mobilenet.pb -is "300,300,3" --autocrop -vv
Option 1: Cropping using the “input” and “output” arguments
Using this option to crop the model is more convenient for cases where the number of inputs/outputs of a model is small and can easily be entered in the command line itself. The --inputs and --outputs are expected to be comma-separated strings. For example, you can crop a single model as,
mx_nc -v -m model_0.pb --inputs "input_0" --outputs "output_0,output_1"
Note
You don’t have to crop both the inputs and the outputs. You can use only one argument if needed.
In the case of multi-models, the inputs and outputs of different models needs to be separated using a vertical separator (|). For example,
mx_nc -v -m model_0.pb model_1.onnx --inputs "model_0_input_0|model_1_input_0" \
--outputs "model_0_output_0,model_0_output_1|model_1_output_0"
Note
The argument-based model cropping option is designed for simpler use cases; it assumes an implicit ordering in the strings entered.
The inputs/outputs are mapped in the order the models are passed to the Neural Compiler.
It is not possible to specify inputs/outputs for a subset of the models and skip the others.
Option 2: Cropping using a config file
The second option a user has to cut their model(s) is the
--model_in_out argument. This flag accepts a
path to a JSON file that specifies how the input model’s graph should be
cropped. The specifications of the model_in_out configuration file are
described in in_out file format.
For details on which name to specify for a chosen layer, refer to Layer specification for Model Cropping
Saving the cropped-out pre/post-processing sections#
As cropping the model removes pre/post-processing layers, the user cannot directly stream input images into the MXA since the pre-processing layers were not part of the model run on the MXA. Similarly, the output of the MXA is not the final output of the model as the post-processing layers were not part of the model that was run on the MXA.
For end-to-end execution of the model, the user needs to run only the pre/post-processing layers on the host processor. The execution flow would then look like: pre-processing (host) -> AI (MXA) -> post-processing (host). The Neural Compiler will attempt to save the cropped-out pre/post-processing sections into separate model files that the user can run directly.
Three different scenarios may occur depending on whether the inputs or outputs were cropped:
When both inputs and outputs are specified for cropping, the Neural Compiler will crop the model into three non-overlapping sections: pre-processing, AI, and post-processing.
When only the inputs are specified for cropping, the Neural Compiler will crop the model into two non-overlapping sections: pre-processing and AI.
When only the outputs are specified for cropping, the Neural Compiler will crop the model into two non-overlapping sections: AI and post-processing.
Note
For this feature to work correctly, it must be possible to separate the model into non-overlapping sections. If the cropper cannot divide the model into non-overlapping sections, the Neural Compiler will display a warning to the user and fall back to extracting just the AI section of the model for the MXA.
See also
Resources Utilization#
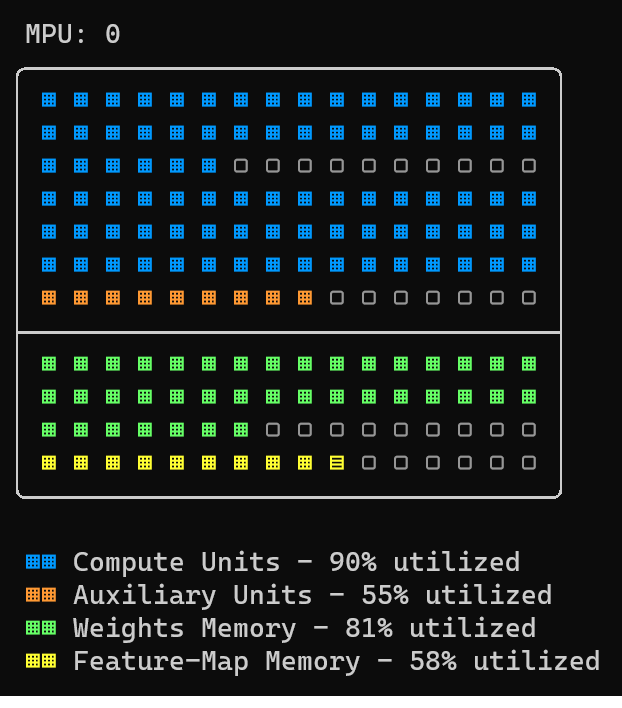
The Neural Compiler allows the user to monitor the MXA resource utilization
during the compilation process. The user needs to use the -so or
-so_aux argument to be able to use this feature. The following figure
shows the utilized resources after mapping a YOLO-v3 tiny model on a single MXA.
Mixed-Precision Weights#
Although activations (feature maps/images) are floating-point in the MXA, weights are quantized per channel to an n-bit integer. The default quantization level is set to 8-bits per weight. The Neural Compiler provides the option to specify the weight precision per layer as 4-bit, 8-bit, or 16-bit. This allows users to optimize their models further as they see fit.
Using the argument --weight_bits_table or -bt of the Neural Compiler, the user can provide the path to the JSON file, which contains weight precision per layer specification. For example,
mx_nc -v -so -m path/to/model -bt path/to/wbits.json
High-Precision Output Channels#
To enhance the precision of the final output-feature-map, utilize the neural
compiler’s High-Precision-Output-Channels (HPOC) feature. It’s sometimes needed for
models with critical output data like pose predictions or detection box
coordinates. This increases precision by allocating extra resources to the last
layer. Activate this with the -hpoc argument, indicating the channels needing
more precision. The compiler will handle the adjustments.
mx_nc -v -m yolov4.h5 -hpoc "0 1 2 3 4 85 86 87 88 89 170 171 172 173 174"
Here, YoloV4’s box coordinates and objectness get improved precision, potentially enhancing accuracy.
For more flexibility, especially with multiple outputs, provide an hpoc_file.json to designate the channels on a per-output basis.
See also
Neural Compiler Extensions#
The Neural Compiler Extensions (NCE) module extends the functionality of the Neural Compiler using supplied .nce files. This enables supporting previously-unsupported-models by impolementing or patching the Neural Compiler functionality. Models that were previously unsupported due to complex subgraph (transformers) or unsupported operators can be now mapped by using the right extension. This allows MemryX to enable users without releasing a new SDK.
Contact MemryX if there is an unsupported model, and we may be able to help you add support for your model by implementing a custom extension. If support is possible, MemryX can supply .nce files to customers as needed to support new or custom operators and to introduce optimized processing steps between SDK releases. In the future, customers will be able to write their own extensions!
Additionally, there are a few builtin extensions which can be enabled for popular models:
If you have a supplied .nce file or are using a builtin extension, supply it using the --extensions argument.
mx_nc -v -m <MODEL> --extensions <EXTENSION>