

Weight Precision#
By default, all layer weights are quantized to 8-bit in MXA. However, there may be models in which the user might want to set the desired precision for the selected layer(s). Currently, two additional levels of precision are offered to the user: 4-bit and 16-bit. This tutorial describes how to set the desired level of precision for selected layers.
Download the Model#
In your Python code, use the built-in API or web to download pretrained models.
from tensorflow import keras
model = keras.applications.MobileNet()
model.save("MobileNet.h5")
import os
import tensorflow as tf
URL = "http://download.tensorflow.org/models/mobilenet_v1_2018_02_22"
TARGET = "mobilenet_v1_1.0_224.tgz"
os.system("wget {}/{}".format(URL, TARGET))
os.system("tar -xvf {}".format(TARGET))
import torch
model = torch.hub.load('pytorch/vision:v0.10.0', 'mobilenet_v2', pretrained=True)
model.eval()
sample_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(model, sample_input, "mobilenet_v2.onnx")
Prepare Weight Precision Configuration File#
View the model with layer names using a visualizing tool such as Netron or the model.summary() method of the respective API.
The layer names will be necessary to prepare the weight precision configuration JSON
file that should be passed with the --weight_bits_table or the -bt argument to the Neural Compiler i.e mx_nc.
The Configuration Files Format section has additional details about the file format of the JSON file.
Let’s use the Keras MobileNet.h5 model. We will set the precision of the first convolution layer of the model to 16 bits
and the precision of the first DepthwiseConv2D layer to 4 bits.
A snapshot of the first few layers of the MobileNet.h5 as viewed in Netron is depicted.
By clicking on a node one can view the node properties. As seen below, the name of the first Conv2D layer is conv1.
Similarly by clicking on the DepthwiseConv2D node you notice that the name of the layer is conv_dw_1
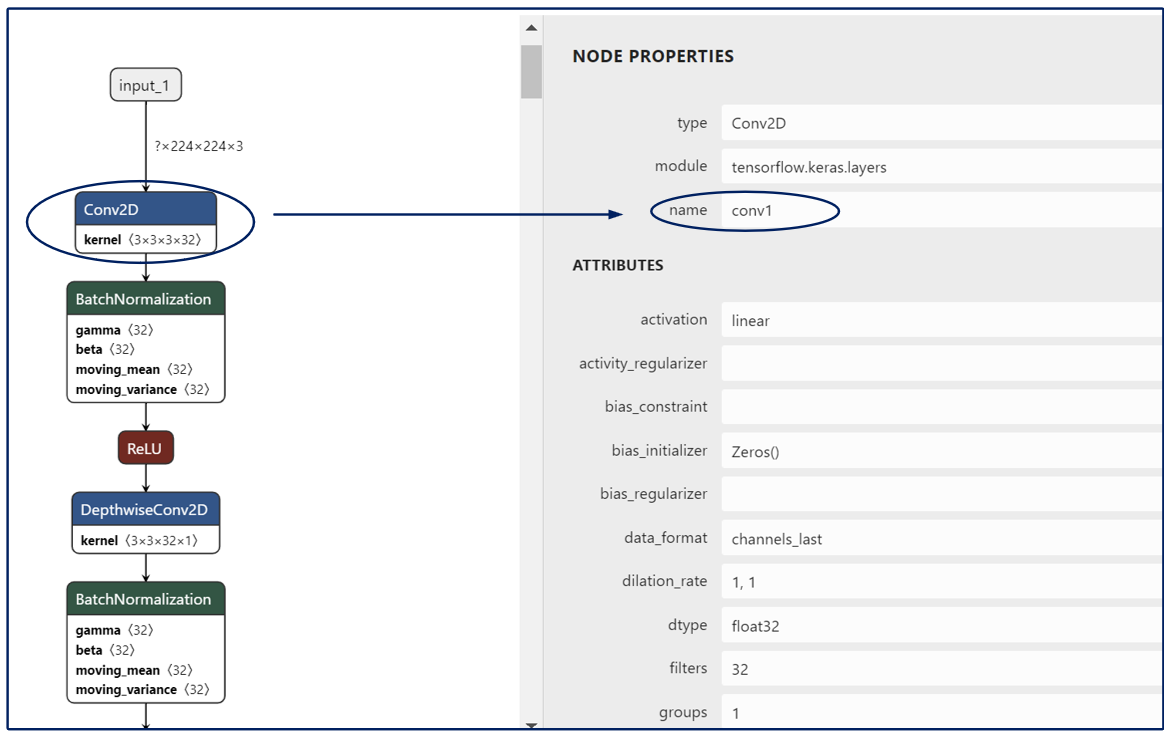
The weight precision file in this case will look like -
{
"conv1": 16,
"conv_dw_1": 4
}
When using Tensorflow models, make sure the graph is frozen before looking at it in Netron to get the layer names. The example below shows how to obtain the layer name from a frozen tensorflow graph.
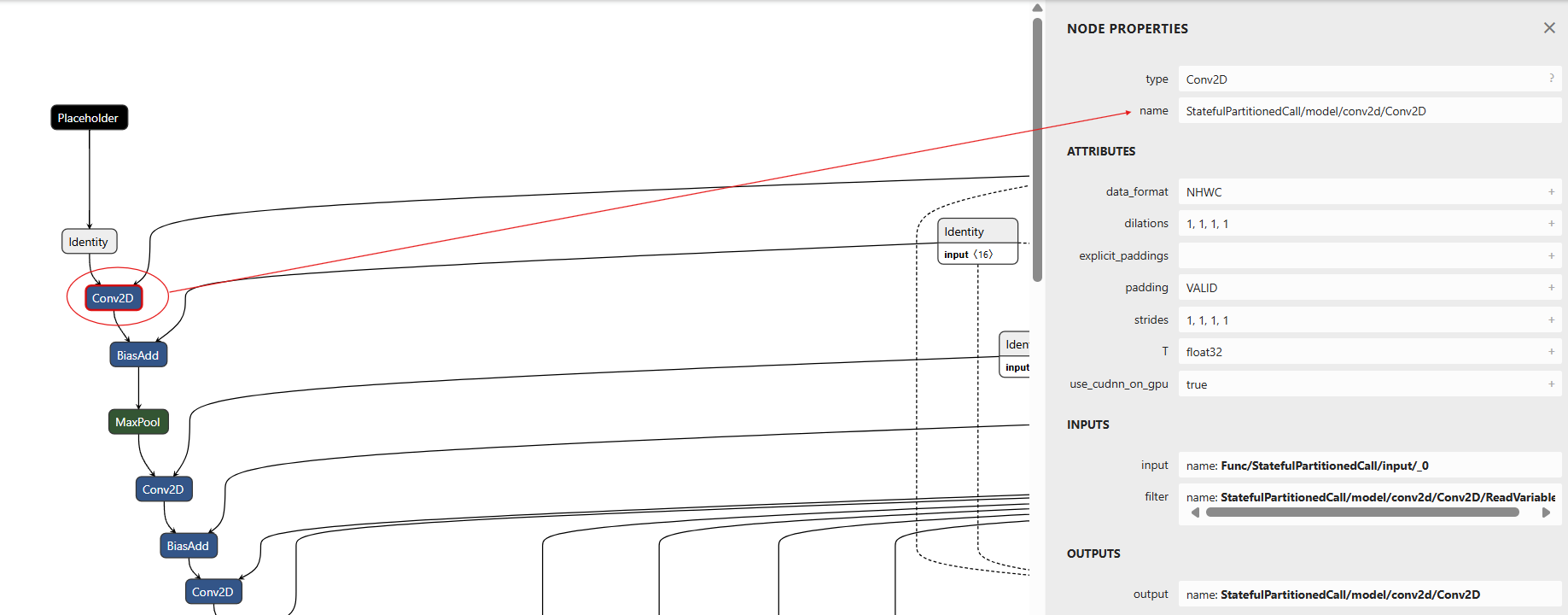
The weight precision file in this case will look like -
{
"StatefulPartitionedCall/model/conv2d/Conv2D": 16
}
When it comes to getting layer names for setting the precision, tflite models behave a little differently. As seen in the image below, we use the name that we see in the outputs tab.
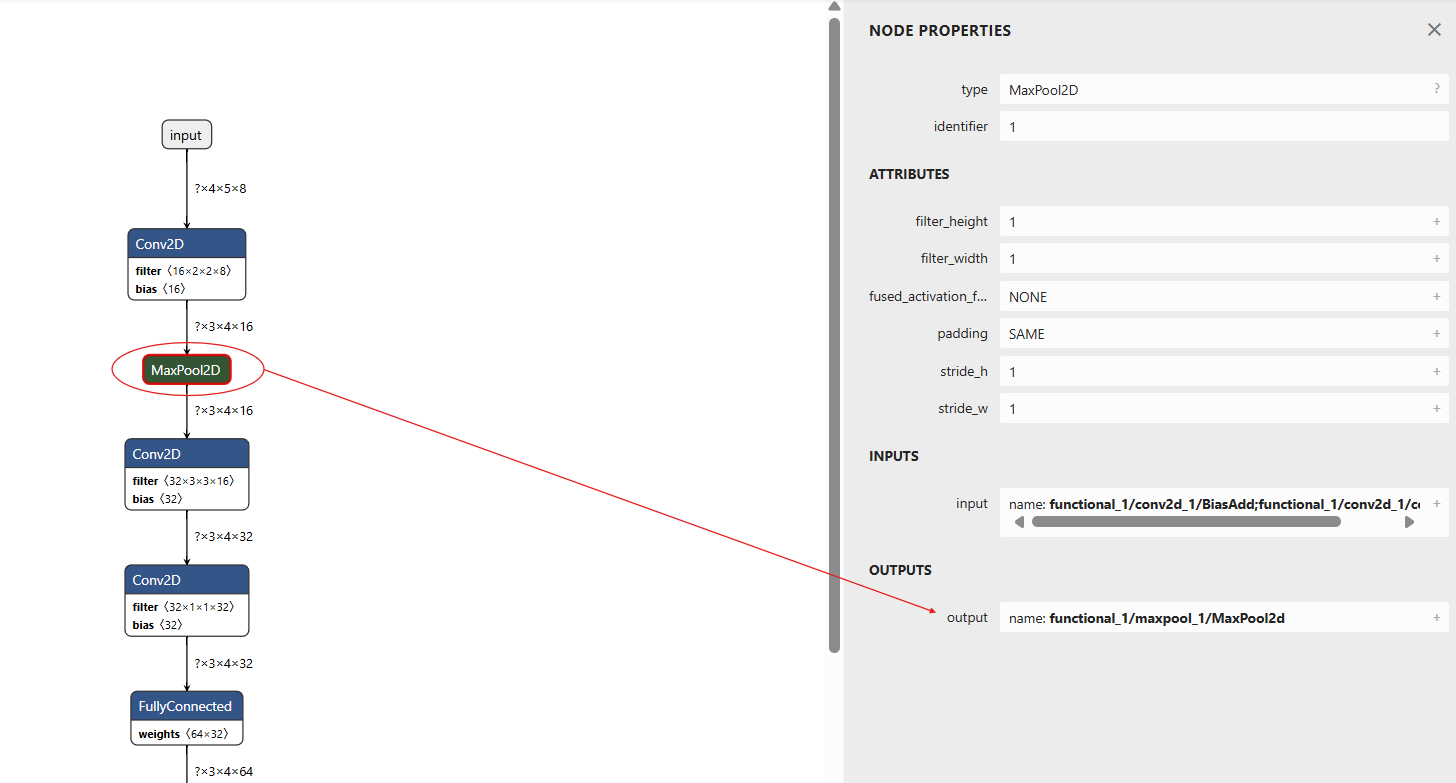
The weight precision file in this case will look like -
{
"functional_1/maxpool_1/MaxPool2d": 4
}
Coming Soon!
Compile the Model with Weight Precision Enabled#
Compile the model and pass the path to wbits.json file with the argument -bt to the neural compiler.
mx_nc -m MobileNet.h5 -v -so -bt path/to/wbits.json