

High Precision Output Channels with YOLOv7#
Introduction#
High Precision Output Channels (HPOC) is an optional technique that can be used to reduce accuracy loss in a subset of models when compiling them for our accelerators (MXAs). Specifically, HPOC increases the precision of certain output channels in the neural network’s output nodes, which can be helpful when a single output contains a mix of information with widely varying value ranges—such as the coordinates and confidence of a bounding box.
Note
It is important to note that most models do not require this technique. HPOC should be used selectively for models where precision is critical for a subset of the outputs. For the majority of models we’ve worked with, HPOC is unnecessary and the standard precision is sufficient to maintain accuracy.
This tutorial demonstrates the application of HPOC using YOLOv7-tiny, showcasing how HPOC can be used to recover any accuracy degradation caused by our efficient GBFloat data format.
YOLOv7 is a popular object detection model that uses a single neural network to predict bounding boxes and class probabilities. It is fast and accurate, making it suitable for real-time applications.
Note
In this tutorial, we use mAP 0.50:0.95 as our performance metric. This commonly used object detection metric calculates the Mean Average Precision (mAP) at various Intersection over Union (IoU) thresholds, providing a comprehensive evaluation of the model’s accuracy. Depending on the application, the mAP calculation can be adjusted to be looser (e.g., at IoU=0.50) or stricter (e.g., at IoU=0.75 or IoU=0.95) to suit specific requirements.
This tutorial is a comprehensive guide to both integrating the MemryX API into an existing codebase and using HPOC to optimize model performance on MemryX accelerators. If you are only interested in the latter, you can skip to the Using High Precision Output Channels section.
When to Use HPOC#
HPOC is beneficial in specific scenarios where the output precision of the Neural Network is critical. It increases the resource requirements of the model on the accelerator. HPOC should be selectively activated on channels requiring more precision, such as box coordinates or pose points. Classifier outputs, segmentation masks, or confidence scores will not benefit as much from the increased precision.
Enabling HPOC#
HPOC is a neural compiler flag and can be used in two ways. The recommended method is to pass a JSON config file with the -hpoc_file flag, which provides more control and is more intuitive than the -hpoc flag, which is easier for simpler cases. The Python and C++ APIs also support HPOC with arguments of the same name.
Note
See the HPOC File Format formatting guide for more information.
Setup#
Download Model and Repository#
For this tutorial, we will work with the official YOLOv7 GitHub repository and the accompanying yolov7-tiny checkpoint which has 6.2 mega-parameters.
git clone https://github.com/WongKinYiu/yolov7.git && cd yolov7
mkdir ckpts && cd ckpts
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-tiny.pt && cd ..
Python Environment#
This tutorial was tested using Python 3.10. Most YOLOv7 dependencies are included with the memryx pip package, and we’ll install a few missing ones manually. Refer to Install Tools to create a virtual environment with the MemryX SDK and then install the additional packages below.
pip install opencv-python==4.11.0.86 pyyaml pycocotools pandas seaborn
Establish Baseline Performance#
Before using the MemryX API, let’s verify the baseline performance of the downloaded checkpoint. The following command runs the evaluation script on the first available CUDA-compatible GPU. The COCO dataset will be downloaded the first time the script is run (~20GB). Modify the data/coco.yaml file if you already have the dataset. Running on CUDA takes a few minutes, while on CPU it takes tens of minutes.
You should get an mAP 0.50:0.95 = 37.3%.
python3 test.py --weights ckpts/yolov7-tiny.pt --device 0 # or --device cpu
... # The first line (mAP 0.50:0.95) is the main number we care about
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.373
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.550
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.400
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.417
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.518
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.571
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.365
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.629
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.744
...
Performance without HPOC#
Before adding HPOC, let’s verify the model’s performance on the accelerator without it. First, export the model to ONNX and compile it into a DFP file to be loaded into the accelerator. Converting all models to ONNX is good practice as it provides a clear model definition. PyTorch checkpoints cannot be compiled directly due to the flexibility allowed in the computation graph.
Compile Model#
Export the model to ONNX and then compile without HPOC. Keep the batch size at 32 for consistency.
python export.py --weights ckpts/yolov7-tiny.pt --grid --simplify --iou-thres 0.65 --conf-thres 0.35 --max-wh 640 --batch-size 32 && cd ckpts
mx_nc -v --autocrop -m yolov7-tiny.onnx && cd ..
Notice the use of autocrop. The ONNX model has post-processing steps not supported on our accelerator but can be run on the host CPU. This post-processing is saved as a separate model called yolov7-tiny_post.onnx.
Modify Evaluation Source Code#
Next we must make a few modifications to test.py and utils/dataset.py to use our MX API instead of torch for inference. We’ve either included the lines before and after the changes or the lines themselves for context.
Note
To avoid manual modifications, you can download the pre-modified scripts from this zipfile. Place test.py in the root directory and dataset.py in utils/.
The following steps are still useful to understand if you wish to integrate the MemryX API into your codebases.
- Add imports at the top of the file:
# test.py # other imports... import memryx as mx import onnxruntime as ort # Optional: makes output more readable import warnings warnings.filterwarnings("ignore") # def test(data,
- We will use
--device mxato run inference on the accelerator. Make the following changes in the main body of the script to support this: # test.py # opt.data = check_file(opt.data) # check file opt.mxa = False if opt.device == 'mxa': opt.device = 'cpu' opt.mxa = True # print(opt)
- We will use
- Drop the last incomplete batch for simplicity and disable dynamic input shapes which are unsupported on the accelerator:
# test.py # Set rect=False and add drop_last=True in the call to create_dataloader in the test function. dataloader = create_dataloader(data[task], imgsz, batch_size, gs, opt, pad=0.5, rect=False, drop_last=True, prefix=colorstr(f'{task}: '))[0] # utils/dataset.py # Modify the function signature of create_dataloder by adding the parameter drop_last=False def create_dataloader(path, imgsz, batch_size, stride, opt, hyp=None, augment=False, cache=False, pad=0.0, rect=False, drop_last=False, rank=-1, world_size=1, workers=8, image_weights=False, quad=False, prefix=''): # utils/dataset.py # Pass the new argument along to the call to loader in create_dataloader. dataloader = loader(dataset, batch_size=batch_size, num_workers=nw, sampler=sampler, pin_memory=True, drop_last=drop_last, collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
- Before the loop over the dataloader in
test, create the necessary runtimes for using mxa: # test.py # jdict, stats, ap, ap_class, wandb_images = [], [], [], [], [] if opt.mxa: accl = mx.SyncAccl('ckpts/yolov7-tiny.dfp') ort_post = ort.InferenceSession('ckpts/yolov7-tiny_post.onnx') # for batch_i, (img, targets, paths, shapes) in enumerate(tqdm(dataloader, desc=s)):
- Before the loop over the dataloader in
- Within the loop, replace the call to
modelwith the following code block. Besides the inference calls, this block includes processing steps to glue together the accelerator, the onnxruntime, and the surrounding pytorch code: # test.py # t = time_synchronized() if opt.mxa: # Pass images through accelerator images = img.detach().cpu().numpy() # (B, 3, H, W) batch = [img[np.newaxis, ...] for img in images] # Expand dimension to (B, 1, 3, H, W) accl_out = accl.run(batch) # (B, 3, 255,Fi, Fi) # Pass accelerator output as input to onnx post-processor onnx_inp_names = [inp.name for inp in ort_post.get_inputs()] onnx_inps = [ np.stack([o[i].squeeze(axis=0) for o in accl_out]) for i in range(len(onnx_inp_names)) ] # (3, B, 255, Fi, Fi) input_feed = {k: v for k, v in zip(onnx_inp_names, onnx_inps)} onnx_out = ort_post.run(None, input_feed) out = torch.from_numpy(onnx_out[0]) # (B, 25200, 85) else: out, train_out = model(img, augment=augment) # inference and training outputs # t0 += time_synchronized() - t
Processing Explanation
We first detach the images (torch tensors) from the graph, bring them to the CPU, and convert them to numpy arrays as expected by both the accelerator and onnxruntime.
We format the batch as a list of images, tranpose each image to be channel-last, and add a singleton dimension for the third spatial dimension. This is the format expected by the accelerator.
The accelerator returns a list of length batch size, of which each element is a list of 3 feature maps. The feature maps themselves are numpy arrays of shape (Fi, Fi, 255) for Fi in [20, 40, 80].
The onnxruntime expects the three inputs (feature maps) to be specified in a dictionary with the correct names so we create a list of 3 numpy arrays. It also expects channel-first format, so we transpose the feature maps accordingly.
Finally, we convert back to a torch tensor to keep compatibility with the rest of the script.
- Within the loop, replace the call to
Run Evaluation on MXA#
This should take a couple of minutes, and you should get an mAP 0.50:0.95 = 35.7%, representing a performance loss of 1.8%.
python3 test.py --weights ckpts/yolov7-tiny.pt --device mxa --exist-ok
...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.357
...
Using High Precision Output Channels#
Recompile the model using the following JSON file. For a detailed explanation of the file format, refer to the HPOC File Format section. In the case of yolov7-tiny, the file is interpreted as follows:
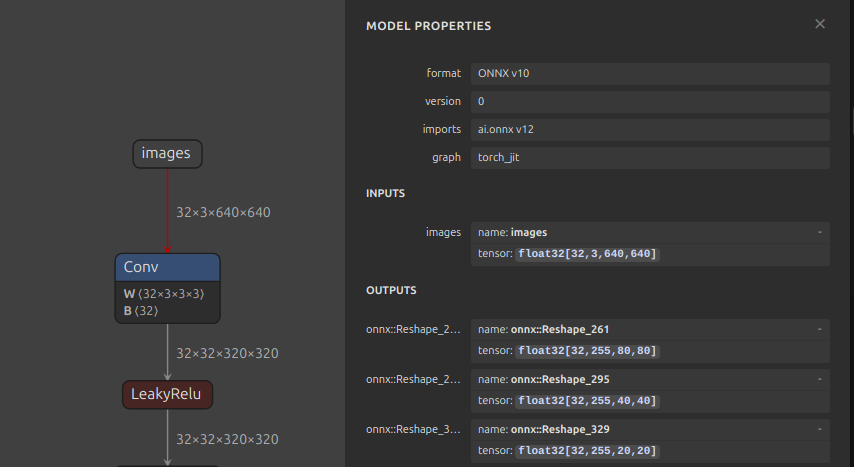
Netron view of yolov7-tiny.onnx with output names in bottom right.#
The top-level
"0"indexes the model to which the settings apply. In our case, there is only one model, so it is simply 0.The dictionary maps the output name to the list of channels in that output to apply HPOC. Use a tool like Netron to inspect
yolov7-tiny.onnxto get each output name.The layer indices are model-dependent. For yolov7-tiny, the layers specified below represent the box coordinates and objectness scores, where precision significantly impacts mAP 0.50:0.95. The remaining layers represent class scores, where precision is less critical as a simple argmax is taken over them.
Create a file called hpoc.json in ckpts/ and paste the following:
{
"0":{
"/model.77/m.0/Conv_output_0": [0,1,2,3,4,85,86,87,88,89,170,171,172,173,174],
"/model.77/m.1/Conv_output_0": [0,1,2,3,4,85,86,87,88,89,170,171,172,173,174],
"/model.77/m.2/Conv_output_0": [0,1,2,3,4,85,86,87,88,89,170,171,172,173,174]
}
}
Note
The specific layer names of the exported Onnx model may be different on your system. Use Netron to check the names of the outputs and adjust the JSON file accordingly.
Recompile using HPOC. Use the dfp_inspect tool to confirm that HPOC has been used.
cd ckpts && mx_nc -v --autocrop -m yolov7-tiny.onnx -hpoc_file hpoc.json
dfp_inspect yolov7-tiny.dfp && cd ..
Run validation with MXA and HPOC to get an mAP 0.50:0.95 = 37%. This represents a significant 1.3% performance gain over not using HPOC and only a 0.3% performance loss from our baseline torch model.
python3 test.py --weights ckpts/yolov7-tiny.pt --device mxa --exist-ok
...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.370
...
Third-Party Licenses#
This tutorial utilizes models and APIs from ultralytics. The licenses for these dependencies are outlined below:
Models: Yolov7-tiny from GitHub
Code and Pre/Post-Processing: Various scripts from GitHub
Summary#
Configuration |
mAP 0.50:0.95 |
|---|---|
Baseline (CUDA) |
37.3% |
Without HPOC (MXA) |
35.7% |
With HPOC (MXA) |
37.0% |
In this tutorial, we applied High Precision Output Channels (HPOC) to the YOLOv7 model to enhance its performance on MemryX accelerators. Initially, the YOLOv7-tiny model without HPOC achieved an mAP 0.50:0.95 of 35.7% on the accelerator, compared to 37.3% using CUDA.
By introducing HPOC through a JSON configuration file and recompiling the model, we observed an accuracy improvement with an mAP 0.50:0.95 of 37%. This closely matches the CUDA baseline with only a 0.3% accuracy loss.
This tutorial demonstrates the effectiveness of HPOC in optimizing model accuracy on MemryX accelerators, achieving near-baseline performance with minimal resource overhead.